大规模核酸取消 感染人数如何预估(大规模核酸检测什么时候开始的)
🔍 1. 大规模核酸检测的兴起与演变:一段全民记忆
⏰ 1.1 时间回到2020年:疫情初期的紧急启动
2020年初,一场突如其来的疫情席卷全球。那时,我们对新冠病毒的认识还非常有限。如何快速、准确地找出感染者,阻断传播链,成了最紧迫的任务。就在这个关键时刻,大规模核酸检测登上了历史舞台。
它的起点清晰烙印在武汉——2020年2月,为了摸清疫情底数,武汉开展了史无前例的全民核酸筛查。这不是一个轻松的决定。面对一种全新的、传播力强的病毒,核酸检测是当时公认的“金标准”。它解决了疫情初期最大的痛点:快速识别传染源。
想想看,没有它,我们就像在黑暗中摸索。大规模核酸提供了那束至关重要的光,让我们能看见“敌人”在哪里。这为后续的精准防控、隔离救治,打下了不可或缺的基础。
📈 1.2 从试点到常态:关键节点推动全民核酸时代
大规模核酸检测并非一夜铺开,它的演变经历了几个关键阶段,深刻塑造了我们的抗疫生活:
1. 探索与局部应用期(2020年初-2020年中): 武汉经验后,国内多个出现聚集性疫情的城市(如北京新发地、乌鲁木齐等)迅速跟进,将大规模筛查作为控制局部暴发的核心手段。混采技术(如“10合1”)的普及极大提升了检测效率,降低了成本,为更大范围推广铺平道路。
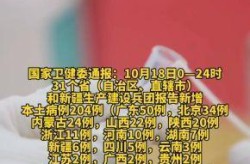
2. 常态化与全国推广期(2020年底-2021年): 随着德尔塔等变异株的出现,传播速度加快。为应对多点散发的复杂局面,大规模核酸检测从“应急之策”逐步走向“常态化防控工具”。特别是2021年下半年的多点散发疫情,使得高频次、大范围的核酸筛查成为许多城市的“标配”。
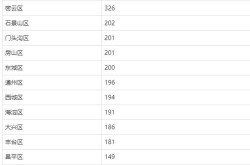
3. 高峰与反思期(2022年): 奥密克戎变异株以其极强的传播力,将大规模、高频率的核酸检测推向了顶峰。“全员核酸”、“多轮筛查”成为高频词。这个阶段,核酸检测在努力追着病毒跑的同时,其巨大的社会成本、资源消耗以及对日常生活的深远影响,也引发了广泛的关注和讨论,成为政策调整的重要背景。
忘不了那段日子: 扫码登记的长队、熟悉的“啊”声、手机里无数的检测记录贴纸...大规模核酸从最初的应急救命稻草,演变成贯穿我们生活数年的集体记忆。它见证了科技的应急力量,也记录下特殊时期的坚韧与付出。这些记忆,恰恰构成了理解后续政策转变的基石。

🔮 2. 核酸取消后的感染人数预估新策略:看不见的敌人,如何追踪?
大规模核酸检测的淡出,留下了一个巨大的问号:没有那根熟悉的棉签,我们如何看清病毒在人群中的真实流动?当全民筛查的“全景图”成为历史,精准预估感染人数,守护健康,需要更智慧、更灵敏的新眼睛和新方法。告别“全员检测”,不等于放弃监测,而是开启了更高效、更可持续的疫情追踪新篇章。
📊 2.1 新眼睛,新算法:替代方法点亮疫情地图
当大规模核酸筛查不再是主力,我们迅速转向了多维度、智能化的监测预警体系。核心策略聚焦在几个关键方向:
- 症状哨兵:发热门诊与网络报告系统成为前哨站。 医疗机构发热门诊就诊量、流感样病例监测数据,是反映社区呼吸道疾病活动水平最直接的“体温计”。国家层面和地方层面都在强化这类数据的实时收集和分析,第一时间捕捉异常升高信号。同时,鼓励居民通过官方APP、小程序自主报告抗原阳性结果或典型症状,汇聚成宝贵的社区健康动态信息流。这解决了“早期预警信号从哪里来”的核心问题。
- AI预言家:大数据与智能模型预测传播趋势。 人工智能和大数据技术站到了前台。利用搜索引擎中“发烧”、“咳嗽”、“抗原”等关键词的搜索量变化,结合药店退烧药、感冒药、抗原检测试剂的销售数据,甚至特定区域人员流动信息,构建复杂的预测模型。这些模型如同“病毒传播的天气预报”,能够提前估算特定区域、特定人群可能的感染规模和高峰时间点。百度、腾讯等科技公司及高校研究团队开发的预测模型,在政策调整初期就发挥了重要的参考作用。这回应了“如何预判疫情走势”的迫切需求。
- 多源数据融合:拼出更完整的疫情拼图。 单一数据源存在局限。将症状监测数据、网络报告数据、重点机构(如学校、养老院)监测数据、甚至部分保留的必要人群(如医疗机构工作人员)核酸抽检数据,进行交叉验证和融合分析。通过数据间的相互印证和校准,显著提升了疫情态势评估的整体性和可靠性,弥补了单一渠道的不足,解答了“如何更接近真实感染规模”的难题。
🧩 2.2 成长的烦恼:数据缺口与精准估算的挑战
新策略展现出强大潜力,但迈向精准估算的道路并非坦途,几个关键挑战亟待突破:
- “沉默数据”的缺口:无症状感染与自测报告率是盲区。 最大的挑战在于“看不见”的感染者。大量无症状感染者可能从不就医、不自测或不报告。即使出现症状,依赖抗原自测的人群中,主动上报的比例也难以保证。这造成了实际感染规模被系统性低估,精准估算面临“数据源先天不足”的困境。
- 数据代表性与偏差:谁的声音被听到了? 当前依赖的数据源存在代表性问题。主动报告症状或抗原结果的人群,可能更关注健康、更熟悉使用智能设备(如年轻人),而老年人、信息闭塞人群、偏远地区居民的声音容易被忽略。搜索引擎和药房数据的用户群体也存在特定画像。这种采样偏差直接影响模型预测结果的普适性和准确性,可能导致对某些人群风险的低估。
- 模型校准与动态优化:病毒在变,模型也要变。 AI预测模型的精度高度依赖于历史数据的质量和模型的持续训练。新冠病毒不断变异,人群免疫背景(自然感染、疫苗接种)也在动态变化,这意味着预测模型需要高频次地重新校准和优化。否则,基于旧数据训练的模型,在新环境下可能失效,导致预估结果偏离现实。
- 未来之光:构建更强大的综合监测网。 面对挑战,未来方向清晰:打造更完善、更智能的综合监测预警系统。这包括:大力提升居民自测上报的便捷性和积极性;扩大基于人群的血清学调查(测抗体),摸清人群免疫本底;深化多源异构数据的融合技术与标准;持续投入研发更鲁棒、自适应能力更强的AI预测算法。国家正在建设的传染病智慧化多点触发预警系统,正是朝着这个目标迈进的关键一步。
告别棉签,拥抱智慧: 大规模核酸曾是特殊时期的“重器”,它的功绩不容抹杀。如今,我们正逐步学会用更轻便、更可持续的“组合工具”来监测疫情。新策略虽然还在成长,面临挑战,但它代表了科学防控走向常态化、精准化的必然趋势。每一次数据的上报,每一次模型的优化,都在让我们更清晰地“看见”病毒的轮廓。告别全民核酸的长队,我们并非在黑暗中行走,而是用更智慧的双眼,继续守护彼此的健康之路。精准防控的探索,永不止步。
本文系作者个人观点,不代表本站立场,转载请注明出处!